Stop corrupting yourself: test against abstractions
Regression tests are important, but why, exactly?
This is an important question to answer up front; as the answer to this question is exactly why the testing strategy I will describe later is so beneficial. So then, why exactly are we all enamored with the idea of writing automated regression tests?
Regression tests ensure that your code maintains correctness as it changes.
This simple definition outlines the value proposition of regression tests, but there are many different circumstances in which regression tests are useful:
- You’ve already written code which is correct, and you want to ensure it stays correct as you change it.
- You’ve already written code, but it’s incorrect. As you fix bugs, you wish to ensure the specific bugs you’ve already fixed don’t sneak their way back into the code over time as you change it.
- You haven’t written code yet, but you have defined what it means to be correct, so you wish to ensure that your implementation is correct as it is written (this is a fancy way of describing Test-Driven Development [TDD]).
Code changes
Did you pick up on the theme in the above list of circumstances in which you might want to write regression tests?
Just in case, let me state it explicitly:
Regression tests only deliver value when the code under test changes.
This seems self-evident, but yet, it’s nonetheless extremely easy to forget this fundamental value proposition when writing regression tests, thus undermining your own efforts.
Here are a few ways in which this commonly happens:
- Tests are too narrowly focused such that the code under test never changes.
- Tests are tightly coupled to the implementation of the code being tested such that each time the code being tested changes, the tests must change too.
- Tests are written with out-of-process dependencies such that the signal-to-noise ratio of your tests is reduced by temporally coupling your tests to uncontrollable dependencies.
Let’s talk about signal
What are we signaling by broadcasting the passage (or failure) of automated regression tests?
It’s tempting to think that our tests are signaling correctness of implementation: passing tests mean we have a correct implementation while failing tests mean we don’t, but that’s not quite right; there’s an ambiguity problem with thinking tests signal correctness: just like the code under test can change, the tests themselves can change. Also, of course not all code changes are accidental, but one might accidentally forget to update tests in turn. Thus, observing the passage (or failure) of automated regression tests tells you no more than the following: something changed (or didn’t change).
Test results signal change (with some necessary ambiguity).
Thus far, this post may seem like an exercise in pedantry, but understanding the simplicity of the signal and the value proposition from regression tests is critical in avoiding common pitfalls of tests being too narrowly focused, tests being strongly coupled to implementation, or tests including too many dependencies which add noise to the signal.
Let’s talk about each of these problems in a bit more detail.
1. Tests that can’t fail
I won’t spend much time on this common pitfall of regression testing, because frankly, it’s a pretty simple problem.
The problem is simply testing code with too narrow a focus, such that the code being tested is so simple that it never needs to change and is extremely unlikely to ever be incorrect.
An extremely silly (and contrived) example of this might be testing the addition operator of your chosen programming language. Is the addition operator critically important to your application logic? Almost certainly. Most applications will add numbers together at some point and depend heavily on the correctness of this operation. Can the behavior of the addition operator change? Yes. It’s not particularly likely that it will, but it could.
So what’s the problem here? The problem is the narrow focus. You can’t see the forest for the trees. You’re testing one tiny bit of minutia present in your application logic with such a specific focus that you’re gaining no value in the exercise; that is, this detail won’t change, and likely shouldn’t change. So why are you regression testing it? (Remember our value proposition?) Besides, surely you can receive a signal if this detail changes with tests that exist at a higher level if this detail is in fact, important. More on that later.
Side note: Testing minutia that’s presumed to be correct and stable isn’t worthless, it’s just an investment with strongly diminishing returns for most developers who don’t have the luxury of spending infinite time writing tests. Stable code presumed to never need to change should be low on the testing priority list.
2. Tests that can’t survive
Tests that can’t survive are tests that are tightly coupled to the code they’re testing. With unit tests, this coupling is structural. That is, your tests are directly calling the code being tested. Your tests are not only aware of the API being tested (the inputs and outputs), but of the implementation details of the API, and they will assert directly against those details.
This causes volatility in test code. Every time you change the implementation details you necessarily must change the accompanying tests.
This effort doesn’t scale well. We already know that we’ll be changing code over time. Let’s say we’re going to change the code n times. That means our baseline maintenance effort is linear, O(n) just for having code we change over time. When we add tests to that code, and the tests themselves are structurally coupled to the code being tested, this means each time we change the the code we must also change each test coupled to that code’s structure. If there are m structurally coupled tests to code we’re changing n times, that means our maintenance burden is multiplied by the number of tests, O(n * m). When you think of the runtime complexity of this algorithm, if you’re not scared of that multiplier, remember that this algorithm is performed manually by humans. Specifically, you, the developer trying to maintain that code. Remember, that multiplier increases with each and every test that you add. It’s no wonder people often resent automated tests or don’t see the value in them; if you live in a world in which each test you write multiplies the overall maintenance burden of the code being tested, that’s a reasonable reaction.
There is a more subtle problem here too: writing tests directly against the implementation details of existing code as a matter of practice carries with it the inherent assumption that the existing code is correct. This is a dangerous assumption, especially because it’s not necessarily explicitly stated either, leading to test authors making this assumption without even realizing it. That is; it’s very easy to become blind to bugs if what you’re testing isn’t that the code does what it’s supposed to do, but rather, that the code does what it currently does. The insidiousness of this problem isn’t that test authors have bad intent or an inability to spot bugs, but rather, by peering into the implementation details of the code under test so as to (presumably) lock in that behavior with the tests being authored, you’re stacking the deck against yourself in favor of mistakes by not giving yourself the cognitive relief of thinking about your own code as if you were an outsider, unaware of how it works.
When it comes to testing, being intentionally ignorant of how your own code works under the hood is a feature, not a bug.
3. The test that cried wolf
Tests that cry wolf are tests with a poor signal-to-noise ratio.
Noise in automated tests is the single most effective way to undermine your own efforts. Introducing tests that are non-deterministic — that is, testing the same version of the same code, with the same inputs, and not being able to guarantee you always get the same test results — will cause anyone observing your test results to lose all faith in that signal, and rightfully so.
Tests that are noisy are in fact worse than having no tests at all, since the absence of tests tends to make people act carefully and test manually, while the presence of noisy tests makes people more complacent (rationalized by the presence of automated tests) while only operating under the illusion of safety from automated tests.
Noisy tests are the result of testing too large of a unit with too many out-of-process dependencies. These often take the form of end-to-end or integration tests, where the passage of a test is temporally coupled to the availability of other running processes like a database, a cache, session state, other internal microservices, or even external APIs which are particularly problematic because they’re not even under the control of your own organization. Further, these type of tests are often coupled to the availability of specific test data which must be carefully controlled and orchestrated to be available at the right time in your test environment and hopefully cleaned up afterward.
To be clear: testing with some external dependencies is fine, and in fact, encouraged. The problem of tests that cry wolf emerges when tests have so many of external dependencies in scope that the likelihood of a given test failure being caused by an environmental issue instead of a code change nears 100%.
Signs that your tests are crying wolf:
- Test failures are mostly unexpected
- Test failures almost exclusively appear unrelated to a change that preempted the failure
- The first action in response to a test failure is to re-run the failed test without changing anything
- Especially if the above strategy actually works
So then, how can we write tests which avoid these pitfalls? Here’s the simplest form of the answer:
Test your system through logical abstractions.
What do I mean with that statement, exactly?
Abstraction should be a term familiar to any developer, but let’s restate it anyway, as I find the finer points valuable for introducing this testing strategy: an abstraction is a simplified view of something more complex. Good abstractions serve to simultaneously document capabilities while hiding implementation details. Good abstractions lessen the cognitive load of developers working with those abstractions.
What should be in my abstraction?
This is a tough question with no quick answers and no definitive rules.
That’s a good thing.
Abstraction is, unto itself, an art form. No two disparate systems will be abstracted alike. There are no shortcuts here.
The answer to this question is as simple as it is unsatisfying: time and effort spent in the creative pursuit of useful abstraction.
Abstraction is simplification. Abstractions expose behaviors and hide details.
To create an abstraction of your own system is to document which behaviors of your system are important and which are unimportant implementation details to be hidden.
Those behaviors which are exposed via the abstraction can be tested, while those that aren’t, can’t. Choose carefully.
Stop corrupting yourself.
Design the abstraction without looking at the details of your system. Preferably, create it first, before implementing the system.
The system you’re writing an abstraction for testing might already exist. That’s fine. Ignore it.
Having as little knowledge as possible about the existing system while writing tests is what makes these tests particularly potent. By being willfully ignorant to the details of the existing system, you’re not documenting what the system does, you’re documenting what the system should do. Isn’t that what you want to ensure, after all?
This is the “anti-corruption layer” pattern. This will be ubiquitous nomenclature in the Domain-Driven Design community, but perhaps its use for testing is novel. Regardless, let’s take a look at this powerful pattern:
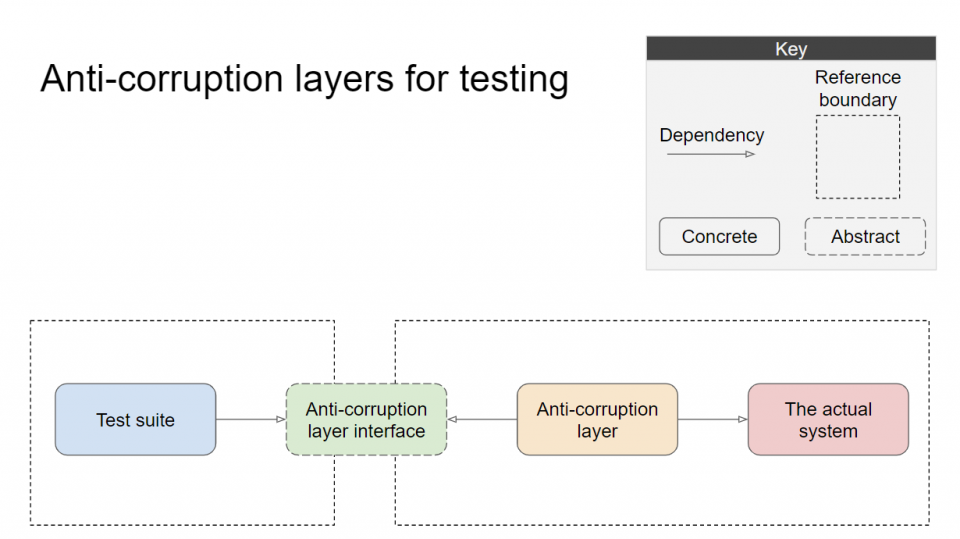
The key points to this pattern are:
- Your tests can’t directly call the concrete implementation of the system under test.
- Your tests can’t know the implementation details of the system under test.
- The dependency between your tests and the system is broken.
- The tests are stable and impervious to changes of the system.
- Tests only must change when the anti-corruption layer interface changes, i.e. when you intentionally change the documented behavior of your system rather than an implementation detail. That is, rarely.
There are few subtleties to the benefits to this approach worth mentioning.
First, because the anti-corruption layer pattern breaks the dependency between your system and its tests, the effort required to maintain tests after each code changes from a linearly complex effort O(n), to a constant time effort O(1). Or, over time, this reduces your overall maintenance to a linear effort, O(n), where n is the number of times you change your tests. The number of tests is no longer a factor in maintenance.
Without the anti-corruption layer pattern — when your tests are coupled to the implementation details of the system — each change to the system’s implementation details may cause tests to fail. Often many tests fail in response to a single change. To ensure these tests pass again is an individual, test-by-test effort, that involves changing the tests themselves. This effort is repeated with each change.
With the anti-corruption layer pattern, large numbers of tests might still fail in response to a single change to the implementation details of the system, but because all tests call your system through a common abstraction, only that common abstraction’s single implementation — which lives outside the test suite’s reference boundary — needs to change for all the tests to pass again. To put it simply: with the anti-corruption layer pattern, when tests fail because implementation details change, you never have to touch test code in order to make the tests pass again. There’s only ever one thing to fix when tests fail for expected reasons (code changes), and that is: the concrete implementation of the anti-corruption layer.
But wait, isn’t the anti-corruption layer itself test code?
Yes and no; mostly no.
What the anti-corruption layer truly is, is a client of your system.
By “client”, I mean something that works with your system from the outside. This particular client just happens to be written for the express purpose of facilitating automated testing. Other clients, like REST APIs or web pages, are designed for other purposes.
The test suite doesn’t know how this client or the system works, and it can’t because it doesn’t have a reference to either. The client is more a part of the system itself than the test suite, and in fact, herein lies the second more subtle benefit to this pattern: the mere existence of the anti-corruption layer for testing creates an incentive to design the actual system’s API similarly to that of the anti-corruption layer.
This is particularly useful when you’re adding tests to the dreaded “legacy” existing system.
In this scenario, it’s quite likely that the legacy system’s API doesn’t easily support automated testing, and as a result, the implementation of an anti-corruption layer can be quite complex. In the beginning, this makes the anti-corruption layer difficult to realize, but what you gain by doing so is a road map for refactoring the legacy system later (you are planning on doing that, right? Otherwise, why are you adding these tests?).
The anti-corruption layer’s implementation will never add complexity to a system, but it will, necessarily, encapsulate it. It follows then, that to improve the testability of the legacy system, merely change it so as to reduce the complexity of the anti-corruption layer.
What level of tests are these?
Are tests against an anti-corruption layer unit tests? Integration tests? End-to-end tests?
The answer, is yes.
OK, but really, the idea of testing against an abstraction using the anti-corruption layer pattern doesn’t necessarily force you to test at any particular level. The abstraction is purely logical.
By removing the dependency of your own system from your testing suite, you can take the same test suite, swap in a different anti-corruption layer implementation, and run the same test suite at different levels. You can even implement your anti-corruption layer in such a way that your tests are a mixture of different levels in one test suite, perhaps mocking out external dependencies, but keeping internal integration points, even selectively changing strategies between tests.
Design is hard; bring the pain.
These are my parting thoughts before concluding this post. I’ve said it before and I’ll say it again, “bring the pain” is something I consider to be a fundamental principle of software development: if it hurts, do it more often.
Design is painful. It takes time, and effort. That’s a good thing.
To implement an automated test suite for a complex system without taking on the pain of simplifying that complexity into an easily consumable abstraction is to write tests that lock in what the system does rather than what it should do.
If creating this abstraction is easy, you win. You’ve invested a small, fixed amount of time creating the abstraction, and will receive in turn an unbounded return on investment as your tests are now fundamentally less complex to maintain over time.
If creating this abstraction is difficult, you win even more. You gain the same unbounded maintainability benefit, but with the added benefit of having challenged your own preconceived notions of correctness to ensure actual correctness without being blinded by knowledge of the current implementation details; plus you have a refactoring road map in the form of the anti-corruption layer interface.
Pingback: online casino real money mac
Pingback: 100 mg generic viagra
Pingback: buy generic cialis
Pingback: cheap 10mg cialis
Pingback: sildenafil 25mg
Pingback: canadian pharmacies cialis
Pingback: cialis pills women
Pingback: sildenafil 50 mg tablet buy online
Pingback: what do fake viagra pills look like
Pingback: cheap viagra canadian pharmacy
Pingback: prescription drugs without prior prescription